hbm黄金风口,你赶上了吗?-yb体育app官网
来源:全球半导体观察 原作者:竹子
hbm俨然成为了当前存储行业竞争中最为鲜美的一块蛋糕。近日,台积电宣布结合n12ffc 和n5制程技术,生产用于hbm4的基础裸片,为hbm 4做好扩产准备,并且cowos先进封装产能多次扩产,只为满足行业高涨的hbm需求。三大存储原厂也动态不断,此前sk海力士、三星、美光均表示近两年hbm产能已售罄,近期,三星和sk海力士两家表示为了满足需求,他们将超过20%的dram产线转换为hbm产线。随着hbm3e和hbm4的持续推进,带动行业生态发生变革,三大存储原厂与台积电比以往更加紧密的联系在一起。
一、优异性能把持下,hbm势不可挡
业界有把hbm归入先进封装行列的,但更多是把hbm纳入新型存储器中。hbm其全称high bandwidth memory,根本而言,是指基于2.5/3d先进封装技术,把多块dram die像叠罗汉一样堆叠起来的新型存储器。至于行业将其归入先进封装,则是因为目前几乎所有的hbm系统都高度绑定台积电先进封装技术cowos。
hbm通过2.5d cowos封装和ai算力芯片结合,充分释放算力性能。除了cowos先进封装技术外,业界目前还有许多强化hbm功能的在研先进封装技术,如台积电的下一代晶圆系统平台cow-sow、sk海力士的hbm以硅通孔技术(tsv:through silicon via)、批量回流模制底部填充(mr-muf:mass reflow-molded underfill)先进封装、三星的非导电薄膜热压缩tc-ncf(thermal compression with non-conductive film)等等。作为影响着hbm产业未来发展的封装技术,下文还将会详细介绍。
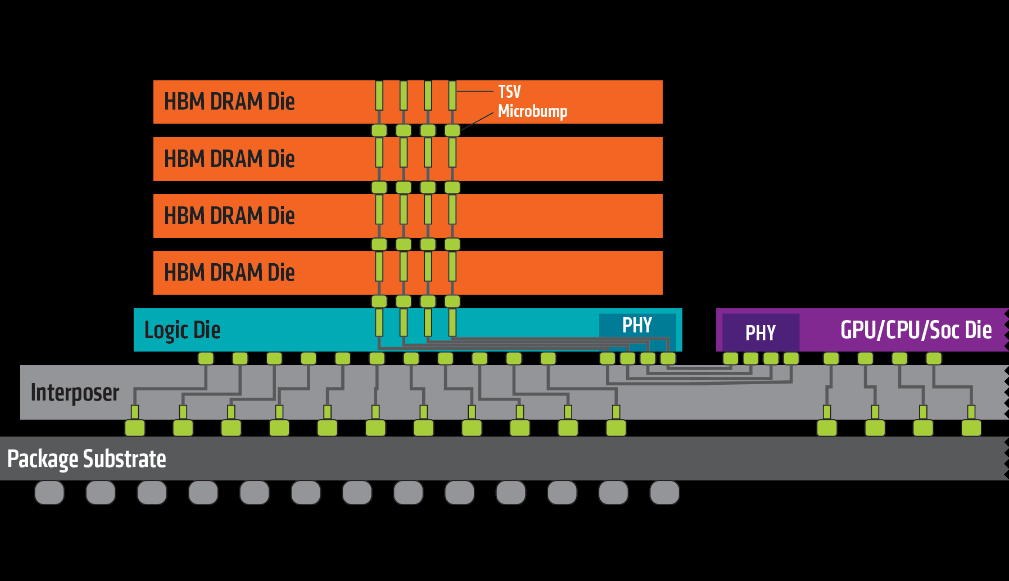
图片来源:amd
如上图所示,hbm是由多个dram堆叠而成,主要利用tsv(硅通孔)和微凸块(micro bump)将裸片相连接,多层dram die再与最下层的base die连接,然后通过凸块(bump)与硅中阶层(interposer)互联。同一平面内,hbm与gpu、cpu或asic共同铺设在硅中阶层上,再通过cowos等2.5d先进封装工艺相互连接,硅中介层通过cubump连接至封装基板上,最后封装基板再通过锡球与下方pcb基板相连。该产品巧妙的设计大大缩小了尺寸面积,容量扩大的同时,实现了高带宽、低延迟、低功耗的效果。
ai时代随着计算需求的不断提升,高端gpu、存储器等需求供不应求。当前gpu补位cpu功能,并不断强化自身算力。但是处理器的性能以每年大约55%速度快速提升,而内存性能的提升速度则只有每年10%左右。目前传统显存gddr5等也面临着带宽低、功耗高等瓶颈,gpu\cpu也算不过来了。
gpu显存一般采用gddr或者hbm两种方案,但行业多数据显示,hbm性能远超gddr。此处来看看amd关于hbm与ddr(double data rate)内存的参数对比,以业界最为火爆的gddr5为例。

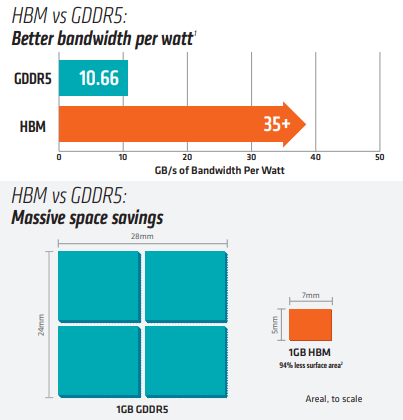
图片来源:amd
根据amd数据,从显存位宽来看,gddr5为32-bit,hbm为其四倍,达到了1024-bit;从时钟频率来看,hbm为500mhz,远远小于gddr5的1750mhz;从显存带宽来看,hbm的一个stack大于100gb/s,而gddr5的一颗芯片为25gb/s。在数据传输速率上,hbm远高于gddr5。而从空间利用角度来看,hbm由于与gpu封装在一块,从而大幅度减少了显卡pcb的空间,而gddr5芯片面积为hbm芯片三倍,这意味着hbm能够在更小的空间内,实现更大的容量。因此,hbm可以在实现高带宽和高容量的同时节约芯片面积和功耗,被视为gpu存储单元理想yb体育app官方下载的解决方案。
但是hbm对比gddr5/ddr5等依旧存在一定劣势。trendforce集邦咨询研究显示,在相同制程及容量下,hbm颗粒尺寸较ddr5大35%~45%;良率(包含tsv封装良率),则比起ddr5低约20%~30%;生产周期(包含tsv)较ddr5多1.5-2个月,整体从投片到产出与封装完成需要两个季度以上。从长远发展角度看,在ai浪潮之下,业界大厂率先考虑抢夺hbm就变得十分合理了。
据trendforce集邦咨询最新研究,三大原厂开始提高先进制程的投片,继存储器合约价翻扬后,公司资金投入开始增加,产能提升将集中在今年下半年,预期1alpha nm(含)以上投片至年底将占dram总投片比重约40%。其中,hbm由于获利表现佳,加上需求持续看增,故生产顺序最优先。但受限于良率仅约50~60%,且晶圆面积相较dram产品,放大逾60%,意即所占投片比重高。以各家tsv产能来看,至年底hbm将占先进制程比重35%,其余则用以生产lpddr5(x)与ddr5产品。
目前hbm已然成为ai服务器、数据中心、汽车驾驶等高性能计算领域的标配,未来其适用市场还在不断拓宽。据trendforce集邦咨询研究显示,产能方面,2023~2024年hbm占dram总产能分别是2%及5%,至2025年占比预估将超过10%。产值方面,2024年起hbm之于dram总产值预估可逾20%,至2025年占比有机会逾三成。展望2025年,由主要aiyb体育app官方下载的解决方案供应商的角度来看,hbm规格需求大幅转向hbm3e,且将会有更多12hi的产品出现,带动单芯片搭载hbm的容量提升。2024年的hbm需求位元年成长率近200%,2025年可望将再翻倍。
二、hbm3e引爆全场,hbm4正在赶来
自2013年sk海力士推出第一代hbm以来,在三大原厂的竞合下,至今已历经第二代(hbm2)、第三代(hbm2e)、第四代(hbm3)、第五代(hbm3e)产品。
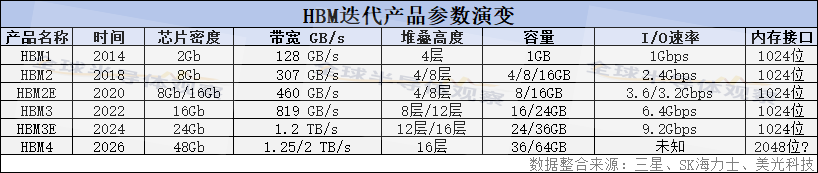
今年hbm3e将是市场主流,集中在今年下半年出货。另外据行业消息,第六代(hbm4)也正在研发中,变革较大,一改一代至五代的1024位内存接口,集中采用2048位内存接口,有望使传输速度再次翻倍。今天我们的关注焦点也将集中在hbm3e及hbm4上。
1)hbm3e霸榜今年
三大存储芯片原厂美光、sk海力士和三星在2023年下半年陆续向英伟达(nvidia)送去了八层垂直堆叠的24gb hbm3e样品以供验证。今年年初,美光和sk海力士的hbm3e都已通过英伟达的验证,并获得了订单。近期行业最新消息传出,因台积电在检测中“采用了基于sk海力士hbm3e产品设定的检测标准”,而三星在hbm中主要采用的是热压非导电薄膜tc-ncf先进封装技术,导致8层hbm3e仍待进一步的检验。三星对此暂无评价。
据trendforce集邦咨询研究,今年hbm3e将是市场主流,集中在今年下半年出货。目前sk海力士(sk海力士)依旧是主要供应商,与美光(micron)均采用1beta nm制程,两家业者现已正式出货给英伟达(nvidia);三星(samsung)则采用1alpha nm制程,预期今年第二季完成验证,于年中开始交付。
2023年8月,sk海力士宣布开发完成hbm3e。今年3月,sk海力士宣布成功量产hbm3e,并在3月末开始向客户供货。据悉,sk海力士的hbm3e在1024位接口上拥有9.2gt/s的数据传输速率,单个hbm3e内存堆栈可提供1.18tb/s的理论峰值带宽。sk海力士先进hbm技术团队负责人kim kwi-wook在近日于首尔举行的ieee 2024国际存储研讨会上表示,以往hbm一直是每两年推进一次,但从第五代产品hbm3e开始,产品周期已缩短为一年。
美光在今年2月26日宣布已经开始量产hbm3e,将应用于英伟达第二季度出货的h200 tensor core gpu。美光消息显示,已经开始量产的产品是24gb 8-hi hbm3e,数据传输速度为每秒9.2gt、峰值存储带宽超越每秒1.2tb。与hbm3相比,hbm3e的数据传输数据和峰值存储带宽提供了44%。并且美光还表示,今年还会推出超大容量36 gb 12-hi hbm3e堆栈。
近日,美光在投资者会议活动上表示,2025年hbm存储器供应谈判基本上已经都完成。美光已与下游客户基本敲定了2025年hbm订单的规模和价格。美光预计hbm存储器将在其截至2024年9月的当年度财报中创造数亿美元等级的营收,而在2025财年当中,相关业务的营收更将成长到数十亿美元。
三星方面,2023年10月,三星宣布推出代号为shinebolt的新一代hbm3e,在今年2月27日,其在其yb体育app官方下载官网宣布开发出了业界首款36gb hbm3e 12h dram,据悉,三星hbm3e 12h dram高达1280gb/s带宽,数据传输速度为每秒9.8gt,领先于sk海力士的9ghz和美光的9.2ghz。加上36gb,较前代八层堆叠提高50%。根据外媒报导,三星已经与处理器大厂amd签订价值30亿美元的新协议,将供应hbm3e 12h dram,预计会用在下半年即将推出的amd instinct mi300系列ai芯片的升级版本instinct mi350上。
结合上述三家原厂hbm3e产品参数看,hbm的变革方向依旧是芯片密度、带宽、层高、容量等方面的提升。目前nvidia的gh200 grace hopper superchip是世界上第一款配备hbm3e内存的芯片,与当前一代产品相比,内存容量高出3.5倍,带宽高出3倍。nvidia还声称,hbm3e内存将使下一代gh200运行ai模型的速度比当前模型快3.5倍。
hbm方面,从nvidia及amd近期主力gpu产品进程及搭载hbm规格规划变化来看,trendforce集邦咨询认为2024年后将有三大趋势。
其一,「hbm3进阶到hbm3e」,预期nvidia将于今年下半年开始扩大出货搭载hbm3e的h200,取代h100成为主流,随后gb200及b100等亦将采用hbm3e。amd则规划年底前推出mi350新品,期间可能尝试先推mi32x等过渡型产品,与h200相抗衡,均采hbm3e。
其二,「hbm搭载容量持续扩增」,为了提升ai服务器整体运算效能及系统频宽,将由目前市场主要采用的nvidia h100(80gb),至2024年底后将提升往192~288gb容量发展;amd亦从原mi300a仅搭载128gb,gpu新品搭载hbm容量亦将达288gb。
其三,「搭载hbm3e的gpu产品线,将从8hi往12hi发展」,nvidia的b100、gb200主要搭载8hi hbm3e,达192gb,2025年则将推出b200,搭载12hi hbm3e,达288gb;amd将于今年底推出的mi350或2025年推出的mi375系列,预计均会搭载12hi hbm3e,达288g。
相较于普通存储芯片,hbm芯片价格相对较高,且有继续上升趋势。trendforce集邦咨询表示,hbm3e的tsv良率目前仅约40~60%,仍有待提升,加上并非三大原厂都已经通过hbm3e的客户验证,故hbm买方也愿意接受涨价,以锁定质量稳定的货源。并且未来hbm每gb单价可能因dram供应商的可靠度,以及供应能力产生价差,对于供应商而言,未来平均销售单价将会因此出现差异,并进一步影响获利。
三、hbm4将给行业带来最新变革
hbm4可看做是hbm技术一个新的分水岭,一方面是hbm领域先进封装技术获得长足发展,更为重要的是产业链出现三大方面的改变。其一,主要内存制造商正计划对高带宽内存技术进行更实质性的改变,一改往常的1024位接口,从更宽的2048位内存接口开始。其二,行业生态改变,三大存储原厂sk海力士、三星、美光与台积电展开高度紧密合作。毕竟在此之前,三家原厂的芯片基本基于本公司自己的制程工艺开展芯片生产。其三,hbm芯片的定制化趋势更为明显。
首先先看看几家大厂hbm4的发展计划以及相关的先进封装技术有哪些。
1)几家大厂hbm4进度几何?
2024年4月19日,sk海力士宣布,公司就下一代hbm产品生产和加强整合hbm与逻辑层的先进封装技术,将与台积电公司密切合作,双方近期签署了谅解备忘录(mou)。5月2日,sk海力士在韩国举行的记者招待会上表示,其hbm4量产时间从2026年提至2025年。具体来说,sk海力士计划在2025年下半年推出采用12层dram堆叠的首批hbm4产品,而16层堆叠hbm稍晚于2026年推出。因为当前距离量产时间还较早,还没有相关产品参数出来。
sk海力士在hbm方面一直处于领先地位,由其主导并采用的hbm以硅通孔技术(tsv:through silicon via)、批量回流模制底部填充(mr-muf:mass reflow-molded underfill)先进封装技术在行业享有盛名。目前随着hbm芯片堆叠层数的增加,mr-muf技术容易翘曲、导致晶圆末端弯曲、空洞现象(即保护材料在某些区域分布不均匀)的问题引起行业高度关注。sk海力士方表示,正在推进tsv和mr-muf的技术发展。与hbm开发初期相比,他们成功地减少了翘曲现象,目前正在开发克服这一问题的技术。下一步,抉择会聚焦在减少空隙。
此外,sk海力士还致力于芯粒(chiplet)及混合键合(hybrid bonding)等下一代先进封装技术的开发,以支持半导体存储器和逻辑芯片之间的异构集成,同时促进新型半导体的发展。当中,hybrid bonding也是被看作是hbm封装的又一个新选择。但根据之前的计划不一样,sk海力士打算在下一代的hbm 4中持续采用尖端封装技术mr-muf。作为替代方案而出现的混合键合技术预计由于hbm标准的放宽而缓慢引入。
三星方面则计划通过针对高温环境优化的ncf组装技术和尖端工艺技术,将16h技术融入下一代hbm4中。据三星的规划,hbm 4将在2025年生产样品。另外据外媒报道,三星在早前的一个会议上表示,正在考虑在hbm 4中使用混合键合或ncf。其认为,混合键合更具优势,因为它们可以紧凑地添加更多堆叠,而无需使用填充凸块进行连接的硅通孔(tsv)。使用相同的技术,hbm上的核心芯片dram也可以变得更厚。
这里值得关注的便是三星在hbm封装上采用的tc-ncf非导电薄膜热压缩先进封装技术。这是一种与sk海力士mr-muf略有不同的技术。在每次堆叠芯片时,都会在各层之间放置一层不导电的粘合膜。该薄膜是一种聚合物材料,用于使芯片彼此绝缘并保护连接点免受撞击。随着发展,三星逐渐减少了ncf材料的厚度,将12层第五代hbm3e的厚度降至7微米(μm)。该公司认为这种方法的优点是可以最大限度地减少随着层数增加和芯片厚度减小而可能发生的翘曲,使其更适合构建更高的堆栈。
美光是这场hbm战局中的半路杀出者,毕竟它一入局,便将目光投向了hbm3。如下图所示,美光晒出了其hbm3e和hbm4产品路线图。方案路线图显示,其hbm4预计在2026年推出,而到2028年则由hbm4e接棒。
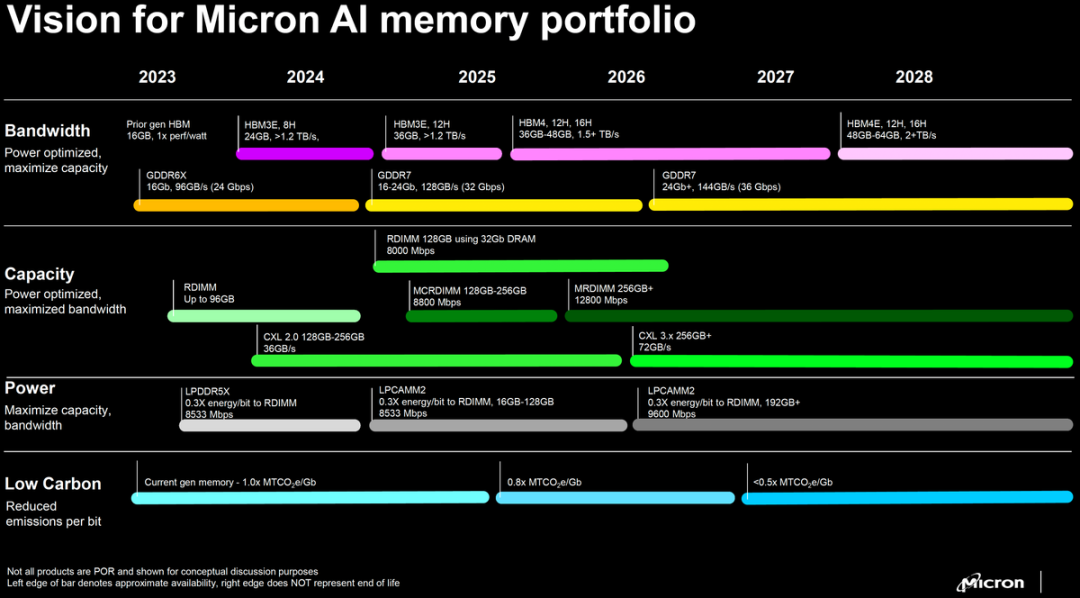
图片来源:美光
关于未来的布局,美光披露了暂名为hbmnext的下一代hbm内存,业界猜测这有可能便是其hbm 4。美光预计hbmnext将提供36 gb和64 gb容量,这意味着多种配置,例如12-hi 24 gb堆栈(36 gb)或16-hi 32 gb堆栈(64 gb)。至于性能,美光宣称每个堆栈的带宽为1.5 tb/s–2 tb/s,这意味着数据传输速率超过11.5 gt/s/pin。
2)产业链三大改变引发行业热议
hbm4时代,产业链出现三大方面的改变近期引起行业热议。
(一)内存接口的重大变革:或将从每堆栈1024位增加到每堆栈2048位
据行业多方消息,组织者正在考虑再次加宽,第六代hbm4接口宽度将从每堆栈1024位增加到每堆栈2048位。自2015年以来,所有hbm堆栈都采用1024位接口。当前的内存接口被设计为宽但较慢的内存技术,在hbm4到来之前,这种以相对适中的时钟速度运行的超宽接口还行之有效,但随着时钟速度的提高,高度并行内存面临着与gddr和其他高度串行内存技术相同的信号完整性和能效问题的风险。
据悉,出于多种技术原因,组织者打算在不增加hbm内存堆栈占用空间的情况下实现这一目标,从而实质上使下一代hbm内存的互连密度加倍。最终结果将是一种具有比当今hbm更宽的内存总线的内存技术,为内存和设备供应商提供了进一步提高带宽而无需进一步提高时钟速度的空间,这将使hbm4在多个层面上实现重大技术飞跃。
采用2048位内存接口,理论上可以使传输速度再次翻倍。例如,英伟达的旗舰hopper h100 gpu,搭配的六颗hbm3达到6144-bit位宽。如果内存接口翻倍到2048位,英伟达理论上可以将芯片数量减半到三个,并获得相同的性能。
总体而言,所有这一切反过来都需要芯片制造商、内存制造商和芯片封装公司之间更加密切的合作,以使一切顺利进行。台积电设计基础设施管理主管dan kochpatcharin在阿姆斯特丹举行的台积电oip 2023会议上发表讲话时表示:“因为他们没有将速度加倍,而是使用hbm4将[接口]引脚加倍。这就是为什么我们正在推动确保我们与所有三个yb体育app官方下载的合作伙伴合作,[使用我们先进的封装方法]验证他们的hbm4,并确保rdl或中介层或两者之间的任何内容都可以支持[hbm4]的布局和速度。因此,我们与三星、sk海力士和美光携手合作。”
(二)台积电与三大原厂密切合作,未来特殊工艺产能扩产,或需建造新的晶圆厂
如上文所说,自hbm4开始,三大存储原厂sk海力士、三星、美光与台积电更加紧密的联系在一起。台积电设计与技术平台高级总监表示,正在与主要hbm存储yb体育app官方下载的合作伙伴(美光、三星、sk海力士)合作,在先进节点上达成hbm4的全堆栈集成。
近期,台积电在2024年欧洲技术研讨会演讲中表示,hbm4将使用逻辑工艺构建,计划采用其n12ffc 和n5制程完成这项任务。另外,cowos先进封装技术还在不断升级,专注于将晶圆级处理器与hbm4内存集成最新封装技术cow-sow也即将推出。
在2024年欧洲技术研讨会演讲中,台积电提供了将为hbm4制造的基础芯片的一些新细节。据悉,台积电表示,该芯片将使用逻辑工艺构建,计划采用n12ffc 和n5两种制造工艺。据悉,n12ffc 具有成本效益的基础芯片可以达到hbm的性能,而n5基础芯片可以在hbm4速度下以低得多的功耗提供更多逻辑。
公开资料显示,台积电采用n12ffc 制造工艺(12nm finfet compact plus,属于12nm制程,但其根源于台积电经过充分验证的16nm finfet生产节点)制造的基础芯片将用于在硅片上安装hbm4内存堆栈片上系统(soc)旁边的中介层。台积电认为,他们的12ffc 工艺非常适合实现hbm4性能,使内存供应商能够构建12-hi(48 gb)和16-hi堆栈(64 gb),每堆栈带宽超过2 tb/秒。
为了适配未来hbm4的产能,台积电表示计划到2027年将其上述提到的特种技术产能扩大50%。该公司在欧洲技术研讨会上透露本周,台积电预计不仅需要转换现有产能以满足特殊工艺的需求,甚至还需要为此目的建造新的(绿地)晶圆厂空间。这一需求的主要驱动力之一将是台积电的下一个专用节点:n4e,一个4纳米级超低功耗生产节点。
另外,提及hbm,必不可少便是台积电的cowos先进封装技术。
cowos封装技术主要分为cow和os两段,其中,cow(chip-on-wafer)指的是芯片堆叠,主要整合各种logic ic(如cpu、gpu、aisc等)及hbm存储器等。wos(wafer-on-substrate)则是将芯片堆叠在基板上,主要将上述cow以凸块(solder bump)等接合,封装在基板上,最后再整合到pcba,成为服务器主机板的主要运算单元,与其他零部件如网络、储存、电源供应单元(psu)及其他i/o等组成完整的ai服务器系统。目前,cowos有2.5d和3d封装版本,以适配企业可以根据需求不同选择不同价格的制程的组合。
台积电高级总监表示,目前正在针对hbm4优化cowos-l和cowos-r技术。cowos-l和cowos-r都使用超过八层,以实现hbm4的路由超过2000个互连,并具有[适当的]信号完整性。n12ffc 上的hbm4基础芯片将有助于使用tsmc的cowos-l或cowos-r先进封装技术构建系统级封装(sip),该技术可提供高达8倍标线尺寸的中介层—足够的空间容纳多达12个hbm4内存堆栈。根据台积电的数据,目前hbm4可以在14ma电流下实现6gt/s的数据传输速率。据台积电表示,该公司目前正与cadence、synopsys和ansys等edayb体育app官方下载的合作伙伴合作,验证hbm4通道信号完整性、ir/em和热精度。
除此之外,台积电还在布局最新封装技术cow-sow。在近期的北美技术研讨会上,台积电推出了下一代晶圆系统平台——cow-sow——该平台将实现与晶圆级设计的3d集成。该技术建立在台积电2020年推出的info_sow晶圆级系统集成技术的基础上。到目前为止,只有特斯拉在其dojo超级计算机中采用了这项技术,台积电表示该计算机现已投入生产。
在即将推出的cow-sow平台中,台积电将在其晶圆系统平台中合并两种封装方法——info_sow和集成芯片系统(soic)。通过使用晶圆上芯片(cow)技术,该方法将能够将存储器或逻辑直接堆叠在晶圆上系统之上。据了解,台积电的cow-sow专注于将晶圆级处理器与hbm4内存集成。这些下一代内存堆栈将采用2048位接口,这使得将hbm4直接集成在逻辑芯片顶部成为可能。同时,在晶圆级处理器上堆叠额外的逻辑以优化成本也可能是有意义的。新的cow_sow技术预计将在2027年实现大规模生产,但实际产品何时上市还有待观察。
然而,行业消息显示,info_sow技术也有着一定的局限性。例如,使用这种方法制造的晶圆级处理器完全依赖于片上存储器,这可能无法满足未来人工智能的需求(但目前来说很好)。cow-sow将解决这个问题,因为它将允许将hbm4放置在此类晶圆上。此外,info_sow晶圆采用单节点加工,该节点不支持3d堆叠,而cow-sow产品将支持3d堆叠。
(三)谈谈hbm4以后的专业化、定制化趋势
在谈及hbm4时,台积电以及sk海力士、三星、美光均提及专业定制化趋势。据悉,目前三大原厂目前与英伟达、amd、微软签订的hbm供应协议早已开启了定制条款。
sk海力士认为,市场将更倾向于专业化(specialized)和定制化(customized)产品,以满足客户需求。他强调,对于新一代hbm,卓越的性能是基本条件,同时,还须具备满足不同客户的特定需求、超越传统存储器性能的优势。
三星则表示,业界越来越认识到,处理器和内存公司各自优化其产品的孤立努力不足以释放agi时代所需的创新。因此,“定制hbm”成为潮流,这也代表了实现处理器和内存之间协同优化以加速这一趋势的第一步。为此,三星利用其在内存、代工、系统lsi和先进封装方面的综合能力。
在刚刚结束的美光科技交流会上,美光透露出一条重磅消息,在hbm产能不足的背景下,业内已经越来越倾向于定制化的hbm产品,主要是因为下游客户越发个性化的需求。为了解决客户对于性能、功能、尺寸、形态、功效等方面的差异化需求,市场将更倾向于打造专业化(specialized)和定制化(customized)hbm产品。
此前,行业针对hbm大规模扩产的行为产生未来是否会过剩担忧。行业人士表示,专业化和定制化可以有效解决这类问题。由于定制化的存储产品与客户需求高度耦合,未来存储厂商和客户会有更深的绑定关系。这一改变可以增加hbm下游供给的确定性,使得存储厂商在做产能规划的时候更有计划性。
-

微信
精彩资讯扫码关注

-

rss
实时更新科技资讯
- 1、「dramexchange-全球半导体观察」包含的内容和信息是根据公开资料分析和演释,该公开资料,属可靠之来源搜集,但这些分析和信息并未经独立核实。本网站有权但无此义务,改善或更正在本网站的任何部分之错误或疏失。
- 2、任何在「dramexchange-全球半导体观察」上出现的信息(包括但不限于公司资料、资讯、研究报告、产品价格等),力求但不保证数据的准确性,均只作为参考,您须对您自主决定的行为负责。如有错漏,请以各公司官方网站公布为准。
- 3、「dramexchange-全球半导体观察」信息服务基于"现况"及"现有"提供,网站的信息和内容如有更改恕不另行通知。
- 4、「dramexchange-全球半导体观察」尊重并保护所有使用用户的个人隐私权,您注册的用户名、电子邮件地址等个人资料,非经您亲自许可或根据相关法律、法规的强制性规定,不会主动地泄露给第三方。
- 「dramexchange-全球半导体观察」所刊原创内容之著作权属于「dramexchange-全球半导体观察」网站所有,未经本站之同意或授权,任何人不得以任何形式重制、转载、散布、引用、变更、播送或出版该内容之全部或局部,亦不得有其他任何违反本站著作权之行为。

 微信公众平台
微信公众平台